E-gazdaság
Az AI-os dokumentumfeldolgozás már nem kísérlet: így dolgoznak a magyar vállalatok napi több ezer számlával, szerződéssel
A legtöbb hazai cégnél még mindig emberek pötyögik kézzel a számlákat az ERP-be, olvasnak át szerződéseket, és válogatnak űrlapokat. Az intelligens dokumentumfeldolgozás (IDP) ezt a munkát automatizálja — nem kísérleti jelleggel, hanem napi több ezer dokumentumon. Megnéztük, hogyan működik a gyakorlatban, és mit jelent ez egy magyar vállalat költségstruktúrájára nézve.
A magyar középvállalatok és nagyvállalatok többsége ma is úgy dolgozik a beérkező dokumentumokkal, ahogy tíz éve: valaki megnyitja a postafiókot, lementi a PDF-eket, kinyitja az ERP-t, és átpötyögi a számla adatait — szállító, dátum, összeg, áfakulcs, fizetési határidő. Ugyanez történik a beérkező szerződésekkel, a kárbejelentő űrlapokkal, az árajánlatokkal és a szállítólevelekkel.
A folyamat lassú és hibalehetőséget kínál. És drága. Nemzetközi beszerzési kutatások (Ardent Partners, Levvel Insights) évek óta nagyjából egyező tartományban mérik a kézi számlafeldolgozás darabköltségét: a teljesen automatizált folyamatokénál nagyságrendileg tízszeres. Egy közepes magyar cégnél, amely havonta több ezer számlát fogad, ez a különbség éves szinten már nem zsebpénz.
A megoldást intelligens dokumentumfeldolgozásnak, angol rövidítéssel IDP-nek (Intelligent Document Processing) hívják. Nem új technológia, de az utóbbi két évben — a nagy nyelvi modellek és a multimodális AI elterjedésével — jutott el oda, hogy érdemes éles vállalati folyamatokra ráengedni. Korábban túl törékeny volt: minden új számlaformátum újabb fejfájást jelentett.
Mi az IDP, és miben más, mint a régi OCR?
A klasszikus OCR (optikai karakterfelismerés) annyit tudott, hogy a beolvasott képből kiolvasta a karaktereket. Ha a számlán szerepelt az „1.250.450 Ft”, azt az OCR átültette szöveggé — de hogy ez most a végösszeg, az áfa, vagy valami egészen más, azt nem értette.
Az IDP ezt a vakságot oldja fel. Egy modern IDP-rendszer egyszerre olvas és értelmez: felismeri a dokumentum típusát (számla, szerződés, megrendelő, kárbejelentő űrlap), kinyeri belőle a strukturált mezőket, validálja az adatokat (van-e ilyen szállító a törzsadatban, egyezik-e a végösszeg a sorelemek összegével), majd átadja az egészet a háttérrendszernek.
A motorháztető alatt négy AI-réteg dolgozik: az OCR a karaktereket olvassa, a számítógépes látás az elrendezést érti (táblázatok, fejlécek, aláírásmező), a természetesnyelv-feldolgozás (NLP) a kontextusból szűri ki, hogy mi micsoda, a gépi tanulás pedig a felhasználói javításokból folyamatosan tanul. Ez a négyes az, ami különbséget ad a hagyományos szkennerszoftver és egy IDP-platform között. Ha valakit mélyebben érdekel, hogyan illeszkedik az NLP a képbe, erről részletesen ír az Omnit egyik szakcikke.
Hogyan néz ki egy IDP-folyamat a gyakorlatban?
Vegyünk egy konkrét esetet: egy gyártócég havi több ezer beszállítói számlát fogad e-mailben.
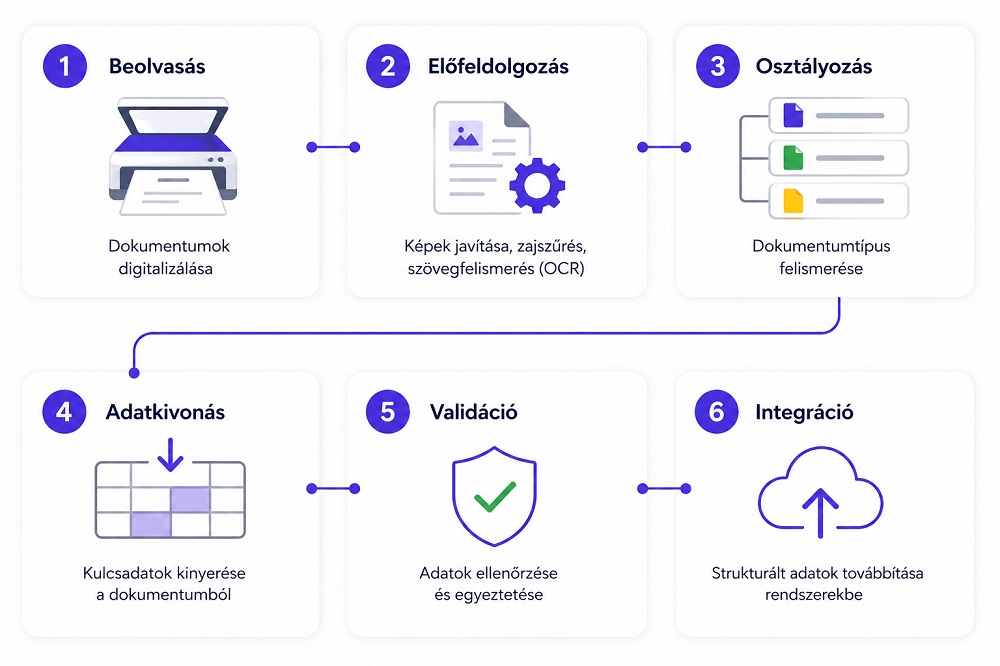
- Beolvasás. A rendszer figyeli a postafiókot, a megosztott meghajtót és az ERP dokumentumtárát. Minden új PDF, JPG vagy beolvasott TIFF automatikusan bekerül a feldolgozási sorba.
- Előfeldolgozás. A rendszer kiegyenesíti a ferdén szkennelt képeket, eltünteti a zajt, és OCR-rel kiolvassa a szöveget. Ezt a lépést szokás lebecsülni, pedig a végeredmény nagyjából innen dől el — szemetes inputból nem lesz tiszta adat.
- Osztályozás. Egy multimodális AI-modell — ami a szöveget és az elrendezést is nézi — eldönti: ez most számla, szállítólevél, vagy szerződés.
- Adatkivonás. NLP- és entitásfelismerő modellek (NER) kiszedik a kulcsmezőket: szállító, adószám, számla száma, kelte, fizetési határidő, áfakulcsok soronként, végösszeg.
- Validáció. A rendszer összeveti az adatokat a törzsadatokkal (létezik-e ez a szállító, jó-e az adószám), ellenőrzi a duplikációkat, és összeadja a sorelemeket. Ha eltérés van, jelzi a könyvelőnek.
- Integráció. A validált adat egyenesen az ERP-be (SAP, Oracle, Microsoft Dynamics, vagy egy magyar fejlesztésű rendszer) kerül, jóváhagyásra előkészítve.
A teljes folyamat — beérkezéstől a könyvelőasztalra kerülésig — percek alatt lefut. Ami eddig egy könyvelő fél napos munkája volt, az most háttérben futó feladat, és a könyvelő csak a kivételeket nézi át manuálisan. Hogy pontosan a számlák hány százaléka az „kivétel”, az nagyon függ a beszállítói körtől és a betanítottság szintjétől — de az érdemi munka itt szépen összezsugorodik. A gyakorlati lépéseket az Omnit dokumentumfeldolgozási oldala is bemutatja.
Hol térül meg leghamarabb?
Az IDP elméletben bármilyen szöveges dokumentumra ráengedhető, de a tapasztalat azt mutatja, hogy három területen térül meg leggyorsabban.
Számlafeldolgozás a klasszikus belépő. A nagy mennyiség, a viszonylag standard formátum és az egyértelmű KPI-ok (átfutási idő, hibás könyvelések száma, késedelmi kamatok) miatt itt látszanak leghamarabb az eredmények. Pluszként elesik a késedelmi kamat kockázata is, mert a számlák gyorsabban érnek el a jóváhagyásig.
Szerződéskezelés és jogi áttekintés a másik nagy terület. Egy nagyvállalat ezerszámra fogad szerződéseket — szállítóit, ügyfeleit, NDA-kat. Az IDP nemcsak kinyeri belőlük a kulcs adatokat (felek, hatály, lejárat, kötbér, szerződéses összeg), hanem kereshetővé is teszi a teljes szerződésállományt. „Mutasd meg az összes olyan szerződésünket, ahol a felmondási idő rövidebb, mint 30 nap” — egy IDP-rendszerben ez perces lekérdezés, nem heteket csúszó jogi átfésülés.

Űrlap- és kárbejelentés-kezelés biztosítóknál, energiaszolgáltatóknál, közszférában. Standardizált űrlapok tömeges, valós idejű feldolgozása — éppen ezért ezen a területen indultak meg a hazai pilot projektek is leghamarabb. Ahogy a technokrata.hu nemrég is beszámolt róla, az UNIQA Biztosító Zrt. már lakáskárügyekben is bevetette az MI-támogatott automatizációt, ami pontosan ennek a technológiacsaládnak az alkalmazása.
Mit ad hozzá az LLM-ek megjelenése?
Az IDP valódi áttörése abban jött el, hogy a nagy nyelvi modellek beépültek a kép-értelmezési folyamatba. Korábban minden új dokumentumtípushoz — új formátumú számla, új szerződésstruktúra — külön be kellett tanítani a rendszert, több száz mintán, hetes-hónapos munkával. Ez volt az IDP-projektek tipikus halálos pontja: a bevezetés után megérkezett egy nagy új beszállító más layouttal, és kezdődött elölről a betanítás.
A modern, LLM-alapú IDP-platformok ezt „zero-shot” vagy „few-shot” módon végzik: néhány példából, vagy akár példa nélkül is képesek értelmezni egy új dokumentumtípust. Nem hibátlanul, de elég jól ahhoz, hogy a kézi javítás már csak finomhangolás legyen, ne újratanítás.
Ehhez társul a RAG (Retrieval-Augmented Generation) technológia, ami lehetővé teszi, hogy a vállalat teljes dokumentumarchívumában természetes nyelven keressünk: „Mit ír a 2024-es bérleti szerződésünk a felmondási feltételekről?” — és a rendszer hivatkozással, oldalszámmal adja vissza a választ. A RAG-ról és arról, hogyan akadályozza meg az AI-hallucinációkat, az Omnit külön cikkben írt.
Felhő vagy on-premise? A magyar piacon ez nem mellékes kérdés
A hazai — és általában az európai — vállalati IDP-bevezetéseknél az egyik legkorábban előkerülő kérdés, hogy hol fusson a feldolgozás: nyilvános felhőben (AWS, Azure, Google Cloud) vagy on-premise, azaz a cég saját szerverein.
A felhős megoldás gyorsabban elindul, és kevesebb infrastruktúrát igényel. Az on-premise viszont kötelező lehet bizonyos adatkörökben — egészségügyi adatok, közszféra, banki belső anyagok, GDPR-érzékeny ügyféladatok — és sok pénzügyi vezető egyszerűen kényelmesebben alszik attól, ha a szerződései nem hagyják el a céges infrastruktúrát. A választás stratégiai súlyát az Omnit külön elemzésben járja körbe, érdemes elolvasni, mielőtt valaki bevezetést tervez.
Mire számítson, aki most kezd hozzá?
Néhány tapasztalat a hazai bevezetésekből, amit jó tudni, mielőtt valaki nekifut.
A bevezetés nem szoftvervásárlás, hanem folyamatváltás. Az IDP-rendszer csak akkor működik jól, ha a jóváhagyási, könyvelési és validációs folyamatokat is hozzá igazítják. A legtöbb sikertelen projekt nem a technológián bukik el, hanem azon, hogy a régi munkafolyamatot rákényszerítették az új rendszerre.
A pontossági arány önmagában félrevezető szám. A 95%-os pontosság jól hangzik, de ha a maradék 5% mindig ugyanaz a tíz problémás szállító, akkor a könyvelő tényleges munkája alig csökken. Egy jó IDP-rendszer megmondja, mire nem biztos, hogy jól dolgozott — és csak azt küldi emberi felülvizsgálatra. A bizonytalanság jelzése legalább annyira fontos, mint maga a pontosság.
A betanítás nem egyszeri esemény. Új szállítók, új formátumok, új áfa-szabályozás folyamatosan érkeznek. A rendszer csak akkor marad pontos, ha a felhasználói javításokból folyamatosan tanul — és ha valaki a cégnél felelős érte, hogy ez ne maradjon abba a bevezetés utáni harmadik hónapban.
És a pilotról: érdemes egy konkrét dokumentumtípuson kezdeni — jellemzően a beérkező számla a legjobb választás —, néhány hónapos kísérleti szakaszban. Ha ott meggyőző az eredmény, lehet skálázni a többi területre. A „egyszerre mindent” típusú bevezetésekből nálunk eddig egyik sem ért happy enddel.
Konklúzió
Az IDP nem új trend, és nem is hype. A hazai nagy- és középvállalatok egy része már évek óta éles üzemben használja, és az eredmények viszonylag konzisztensek: ahol bevezették, ott a dokumentumkezelési költség jelentősen lement, az átfutási idő pedig napokról órákra (sokszor percekre) zsugorodott. A felszabaduló munkaerő — könyvelők, asszisztensek, jogi tanácsadók — nem feleslegessé válik, hanem magasabb hozzáadott értékű feladatokra kerül át.
Aki most kezd hozzá, jövőre már mérhető eredményeket lát. A téma részleteiről, a technológia hátteréről és a hazai bevezetési tapasztalatokról bővebben az Omnit AI-blogján lehet olvasni.
További friss híreket talál a Technokrata főoldalán! Csatlakozzon hozzánk a Facebookon is!